
Every domain has a domain name server handling its requests, and there is a person or IT team maintaining the records in that DNS server’s database. No other database on the planet gets as many requests as DNS servers, and they handle all those queries while also processing data updates from millions of people every day. That’s one of the most amazing parts of DNS — it is completely distributed throughout the world on millions of machines, managed by millions of people, and yet it behaves like a single, integrated database!
Because managing DNS seems like such a big job, most people tend to leave it to the IT professionals. However, by learning a little bit about how DNS works and how DNS servers are distributed across the internet, you can manage DNS with confidence. The first thing to know is what the purpose of a DNS server is on the network where it resides. A DNS server will have one of the following as its primary task:
- Maintain a small database of domain names and IP addresses most often used on its own network, and delegate name resolution for all other names to other DNS servers on the internet.
- Pair IP addresses with all hosts and sub-domains for which that DNS server has authority.
DNS servers that perform the first task are normally managed by your internet service provider (ISP). As mentioned earlier, the ISP’s DNS server is part of the network configuration you get from DHCP as soon as you go online. These servers reside in your ISP’s data centers, and they handle requests as follows:
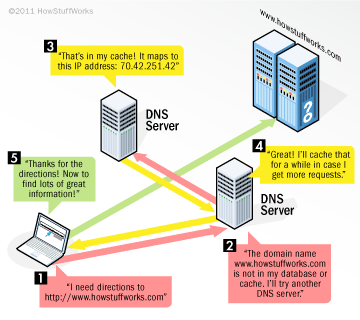
- If it has the domain name and IP address in its database, it resolves the name itself.
- If it doesn’t have the domain name and IP address in its database, it contacts another DNS server on the internet. It may have to do this multiple times.
- If it has to contact another DNS server, it caches the lookup results for a limited time so it can quickly resolve subsequent requests to the same domain name.
- If it has no luck finding the domain name after a reasonable search, it returns an error indicating that the name is invalid or doesn’t exist.
The second category of DNS servers mentioned above is typically associated with web, mail and other internet domain hosting services. Though some hardcore IT gurus set up and manage their own DNS servers, hosting services have made DNS management much easier for the less technical audience. A DNS server that manages a specific domain is called the start of authority (SOA) for that domain. Over time, the results from looking up hosts at the SOA will propagate to other DNS servers, which in turn propagate to other DNS servers, and so on across the internet.
This propagation is a result of each DNS server caching the lookup result for a limited time, known as its Time To Live (TTL), ranging from a few minutes to a few days. People managing a DNS server can configure its TTL, so TTL values will vary across the Internet. So, each time you look up “www.howstuffworks.com,” it’s possible that the DNS server for your ISP will find the lookup results “70.42.251.42” in its own cache if you or someone else using that server looked for it before within the server’s TTL.
This great web of DNS servers includes the root name servers, which start at the top of the domain hierarchy for a given top-level domain. There are hundreds of root name servers to choose from for each top-level domain. Though DNS lookups don’t have to start at a root name server, they can contact a root name server as a last resort to help track down the SOA for a domain.
Now that you know how DNS servers are interconnected to improve the name resolution process, let’s look at how you can configure a DNS server to be the authority for your domain.
Distributed System
A very large number of autonomously managed servers cooperate to :
- independently manage small parts of the global unique DNS Database
- realize the Resolution Algorithm (Database access).
The only centralized point in the DNS system is the initial database entry point defined by the Root zone. Unique root leads to Unique DNS database.
Reliable
Fault tolerance and robustness, redundancy, database replications.
Efficiency
Low traffic, encourage local traffic,h igh distribution for data, caching mechanisms.
Extensibility
large set of Typed Information, high autonomy and independence in management of elementary data.
